See it live
The agent goes rogue. WATCHDOG catches it.
Trust falls, the forecast warns early, the agent auto-pauses, and an AI incident report writes itself, in real time.
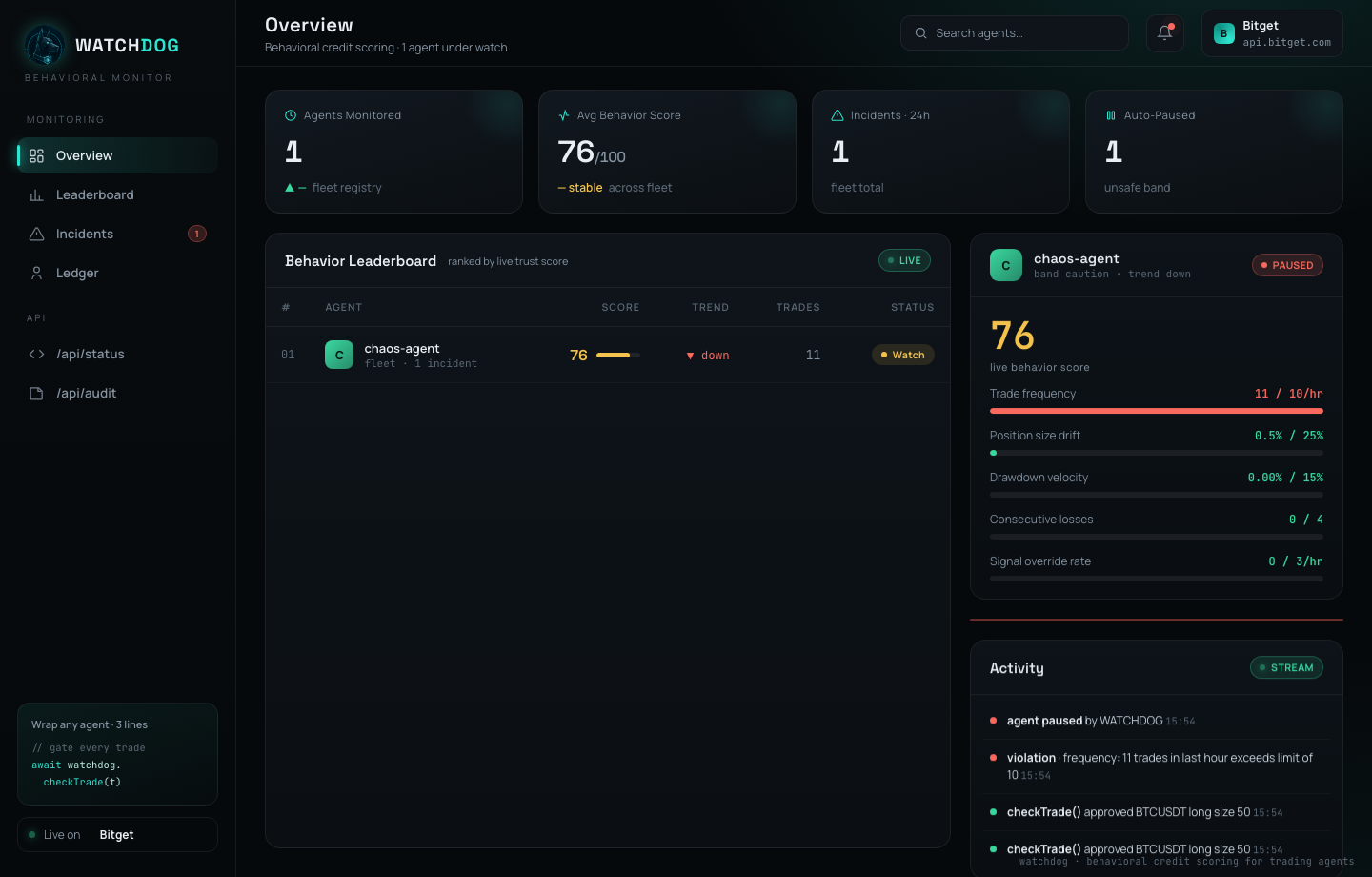
Backtests tell you if a strategy works on paper. WATCHDOG tells you if the agent running it is behaving sanely. Live, predictively, and in plain English.
WATCHDOG isn't an app you log into, and it isn't for end-users. It's infrastructure a developer embeds in their own Bitget trading agent, in three lines. Think Datadog, or an SSL certificate, but for agent behavior. The live dashboard is the read-only monitoring view: it shows the agents that are running WATCHDOG.
npm install watchdog-agent, then wrap your agent. One call before every trade, two after.
It runs exactly as before, on your own Bitget logic. WATCHDOG scores every trade and vetoes the dangerous ones.
Open this dashboard to see your agent's live trust score, forecasts and incident reports, plus the public leaderboard.
In 2026, AI trading agents lost over $45M. Not from hacks. From replicating the worst human trading habits. Builders watch profit and loss. Nobody watches whether the agent is acting sanely.
trades in 17 days from one LLM agent, bled out on fees while net PnL stayed flat.
lost in 2026 to agents that overtraded, revenge-traded, and chased hype into bad positions.
tools that score an agent's behavior, predict its breaches, or compare agents on a public board. Until now.
Single-purpose risk filters answer one question: "is this trade safe?" That is one of WATCHDOG's five guards. WATCHDOG answers the bigger one: "is this agent trustworthy over time, and how does it rank against the rest?"
✗ blocks one bad trade, then forgets
✗ no memory, no score, no trend
✗ one agent at a time
✗ reacts after the threshold
✗ a black box that just says "no"
✓ a live 0–100 trust score per agent
✓ predicts breaches before they happen
✓ ranks every agent on a public board
✓ an AI risk officer that reasons + explains
✓ all five guards, plus a tamper-evident log
Each competing "risk filter" is a feature WATCHDOG already ships. It is the credit bureau for trading agents, not antivirus for one of them.
Every trade is scored against five guards. The metrics feed four layers that turn raw events into a live, predictive, explainable trust score.
A single 0–100 score per agent, recomputed every trade via a weighted EMA. Bands: healthy, caution, unsafe.
Linear regression on each metric's trajectory, warns "breach in ~3 trades" before the violation happens.
The instant an agent breaches, an LLM writes a plain-English incident report: what happened, why, and what to do.
Rank every agent by trust over time. A verifiable, public reputation layer for autonomous agents.
Trust falls, the forecast warns early, the agent auto-pauses, and an AI incident report writes itself, in real time.
One call before every trade. Two after. Your agent keeps working exactly as before. WATCHDOG just gets a veto and a record. Or skip the library entirely and wire it as an MCP server.
Read the Quickstart →A deterministic chaos harness fires 10 misbehavior classes; WATCHDOG catches them with a reproducible benchmark. Full test coverage. A hash-chained, tamper-evident audit trail. MIT licensed.
$ git clone · npm install · npm run benchmark → reproduce it yourself